AWS의 ALB가 서비스의 앞에 붙어있는 경우 다른 서비스에서 해당 서비스에 연동을 할 때 ALB는 내부적으로 트래픽이 줄게 되면 scale in 을 진행한다.
해당 과정에서 제거 된 ALB의 커넥션으로 요청이 가는 경우 502 Bad Gateway를 응답하게 된다.
이런 외부 서비스 연동에서의 외적인 예외 상황은 어플리케이션에서 직접 핸들링 할 수 없기 때문에 어쩔 수 없는 부분이다.
그래서 개발자들은 어플리케이션에서 이런 외부 서비스 연동중 예외 상황에서 재시도를 하여 처리 하게 된다.
관련하여 코드레벨에서 고민하고, 경험했던 사항을 공유 하고 싶어 Spring을 사용하는 환경에 한정하여 Feign Client를 사용하여 외부 서비스 연동시 어떻게 재시도 처리를 할 수 있을지 삽질했던 내용을 공유하려고 한다.
Retry 방식 선택 기준
먼저 Spring 환경에서 재시도 처리를 자체적으로 구현할 수도 있지만,
Spring Retry와 기존에 사용하고 있는 Feign Client에서 Retryer를설정하여 사용하는 방식이 있다.
뭐가 더 좋은지 기준은 상황에 따라 다르겠지만 보통 사용자 요청 실수 같은 경우 재시도를 하는 것은 좋은 선택이 아니며 외부의 일시적 상황에 의해서 실패를 하는경우에 재시도를 하는 것이 보편적으로 합리적이다.
즉, Http 상태코드 500번대 에러를 재시도 처리해주는게 합리적이다.
그렇다면 먼저 자체 구현을 보면, 상태코드까지 확인해야 하고 비지니스 로직을 처리하는 구간에서 반복문과 지역변수 (재시도 횟수)가 낀다던지, 이런게 싫어서 AOP로 구현한다던지.. 고민 해야 할 포인트가 더 많아지고 이는 복잡성을 늘린다.
그래서 자체 구현을 제외하면 Spring Retry 의존성과 Feign Client 내부에서 제공하는 Retyer가 남는다.
문서들을 보면 Spring Retry는 의존성 추가하고 사용할 함수에 Annotation을 지정하면 되는데, Feign Client는 직접 Bean을 등록해야한다.
물론 Spring Retry 의존성을 추가해서 사용하는 것도 좋지만.
처리하려는 사항이 Method 레벨에서 Retry를 하기 위한 것 보다는 외부 연동에서 일시적인 커넥션 순단에 한정되기 때문에 새로운 의존성을 추가하는건 오버엔지니어링 같다는 생각이 들었다.
추가로 Feign 에서 제공해주는 Client를 사용하는 부분을 Wrapping 해주는 별도의 클래스를 만들어야 하는 것도 별로 좋은 모양세는 아니었다. (보통 Client 인터페이스를 주입 받아서 사용하는데 이 사용 부분을 @Retry로 감싸줘야 proxy 객체가 빈으로 등록되며 이걸 사용하는 방식이다.)
따라서, 굳이 새로운 의존성을 추가하는 것 보다 기존 사용하던 Feign Client를 활용하여 Retry를 구현하는 것이 좋아보여서 선택하였다.
구현 중 겪은 문제 사항
Feign Client의 Retryer를 구현하고, Bean으로 등록하였는데 정작 에러가 발생하였을 때 Retry를 하지 않았다.
그래서 그냥 등록하면 되는거 아니야? 라고 생각했었는데.. 왜 이런지 코드로 확인해봐야 잘 알고 사용할 수 있을 것 같아서 내부를 확인해봤다.
코드로 확인한 사항
Client 인터페이스가 구현 된 코드를 실행하는 부분을 확인 해보면,

SynchronousMethodHandler 라는 클래스에서 invoke 메서드를 통해서 HTTP 요청이 실제로 실행된다.
코드를 따라가보면
Retryer는 우리가 Bean으로 등록하거나 기본으로 생성되는 Retryer이고 (설정하지 않으면 Retry 하지 않음)
이객체를 클론하여 사용한다.
클론하여 사용하는 이유는 내부에서 지역 변수로 시도 횟수와 기간 관련 변수들이 존재하는데, 이 변수들을 request 마다 초기화 하고 사용하기 위해서이다.
invoke context 안의 while 루프 안에서
excuteAndDecode 로 HTTP 요청을 하고 응답을 Decode하게 되는데

이 안에서 client.execute 메서드를 통해 요청을 실행한다.
client는 사용하는 클라이언트에따라 다르다. (외부 서버와 소켓 통신을 하고 응답을 받아오는 인터페이스이고.. Apache HTTP Client 5 같은 별도의 구현체를 사용하지 않는다면 Default로 Java 11에서 제공해주는 클라이언트를 사용한다)
Client의 실제 통신 부분은 구현체마다 다르니 생략하고
catch (IOException var9) {
IOException e = var9;
if (this.logLevel != Level.NONE) {
this.logger.logIOException(this.metadata.configKey(), this.logLevel, e, this.elapsedTime(start));
}
throw FeignException.errorExecuting(request, e);
}
catch 부분을 보면 IOException만 캐치하는 모습을 볼 수 있다.
따라서 응답을 받고 응답을 정상으로 파싱한다면 이 부분에 걸리지 않는다.
- 502와 같은 HTTP 상태 코드는 조금 더 낮은 레벨에서 봤을 때 정상적으로 응답을 받은 것 이므로 IOException을 던지지 않는다.
- 즉 Read Timeout이나 Socket Timeout 혹은 Broken Pipe 등등 Low Level 관련 예외들만 이 구간에서 잡히는 것을 확인 할 수 있다.
그러면 저 Catch Phrase 안에서는 어떤 동작을 할까?
throw FeignException.errorExecuting(request, e);
로깅하는 부분을 제외하면 저 함수가 실행되는 것을 확인할 수 있다.
static FeignException errorExecuting(Request request, IOException cause) {
return new RetryableException(-1, String.format("%s executing %s %s", cause.getMessage(), request.httpMethod(), request.url()), request.httpMethod(), cause, (Date)null, request);
}
저 함수 내부를 보게 되면 RetryableException을 던지게 된다.
다시 처음의 실행부로 돌아오면
try {
return this.executeAndDecode(template, options);
} catch (RetryableException var9) {
RetryableException e = var9;
try {
retryer.continueOrPropagate(e);
} catch (RetryableException var8) {
RetryableException th = var8;
Throwable cause = th.getCause();
if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {
throw cause;
}
throw th;
}
if (this.logLevel != Level.NONE) {
this.logger.logRetry(this.metadata.configKey(), this.logLevel);
}
}
여기서는 RetrableException만 Catch 하고 retryer에게 이후 실행을 위임하는 것을 볼 수 있다.
continueOrPropagate() 에서 함수 내용을 보면
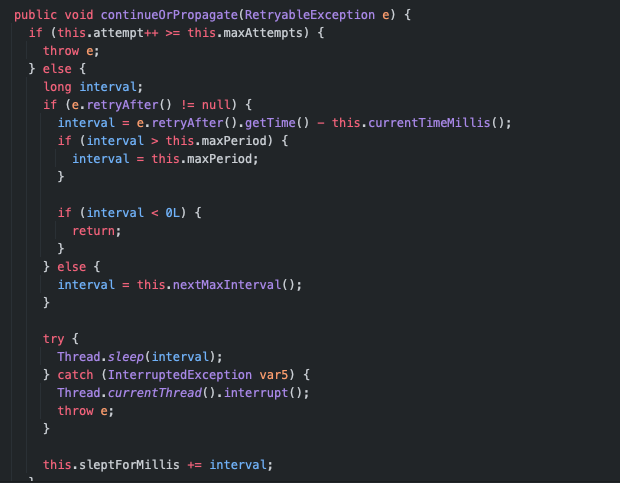
그냥 리턴을 하게 되면 위의 while 루프 안에서 재시도가 되는 것이고
exception을 다시 던지게 되면 루프를 빠져나오게 되는 것이다.
위의 구현체는 interval 동안 대기하고 retry를 하게 되어 있다.
동작 과정을 정리했으니 그러면 어떻게 502 같은 상태코드를 처리할 수 있을까?
우선 위의 excuteAndDecode() 에서 IOException이 아니면
responseHandler.handleResponse(this.metadata.configKey(), response, this.metadata.returnType(), elapsedTime);
여기를 호출하게 된다. 이 함수의 내부를 보면
public Object handleResponse(String configKey, Response response, Type returnType, long elapsedTime) throws Exception {
try {
response = this.logAndRebufferResponseIfNeeded(configKey, response, elapsedTime);
if (returnType == Response.class) {
return disconnectResponseBodyIfNeeded(response);
} else {
boolean shouldDecodeResponseBody = response.status() >= 200 && response.status() < 300 || response.status() == 404 && this.dismiss404 && !this.isVoidType(returnType);
if (!shouldDecodeResponseBody) {
throw this.decodeError(configKey, response);
} else {
return this.decode(response, returnType);
}
}
} catch (IOException var7) {
IOException e = var7;
if (this.logLevel != Level.NONE) {
this.logger.logIOException(configKey, this.logLevel, e, elapsedTime);
}
throw FeignException.errorReading(response.request(), response, e);
}
}
상태코드가 2xx번대가 아니게 되면 decodeError를 호출하게 되는데
private Exception decodeError(String methodKey, Response response) {
Exception var3;
try {
var3 = this.errorDecoder.decode(methodKey, response);
} finally {
Util.ensureClosed(response.body());
}
return var3;
}
내용을 보면 ErrorDecoder에서 decode를 호출하게 된다.
ErrorDecoder는 Customizing 하여 Bean으로 등록해서 사용할 수 있는 부분이다. (Feign Client 문서)
오버라이딩 해서 특정 상태코드를 응답받았을 때 RetrableException을 던지게 되면 IOException 을 만났을 때와 같은 플로우로 동작할 것이다.
HTTP 상태코드 기반 재시도 처리
ErrorDecoder 인터페이스는 BiFunction을 갖는 함수형 인터페이스이기 때문에
람다식으로 Bean을 등록해주면 간단하게 Customizing하여 사용할 수 있다.
@Bean
ErrorDecoder errorDecoder() {
return (methodKey, response) -> {
final var errorMessage
= format("FeignClient Error: %d, %s", response.status(), response.reason());
if (response.status() >= 500 && response.status() <= 504) {
return new RetryableException(response.status(),
errorMessage,
response.request().httpMethod(),
null, // retry delay
response.request());
}
throw errorStatus(methodKey, response);
};
}
이런식으로 등록하면 500 ~ 504 까지의 상태코드에 한하여 retry를 할 수 있다.
'허브 살리기 프로젝트' 카테고리의 다른 글
| 버전 충돌 (4) | 2024.10.24 |
|---|---|
| TopN 구하기 (3) (0) | 2024.10.23 |
| Redis로 Rate Limit 구현 (0) | 2024.06.23 |
| TopN 구하기 (2) (1) | 2024.06.16 |
| TopN 구하기 (1) (1) | 2024.06.09 |
